A Comprehensive Comparison of Meta’s Llama Series and the Classic Transformer Architecture

After revisiting Attention is All You Need, I realized that GPT and Llama are essentially extensions and adaptations of its core ideas. I also appreciate Meta’s transparency in fully open-sourcing the details of the Llama models, which makes it easier to learn from these advanced designs and understand the thought processes behind their architectural decisions.

It took me some time to revisit “Attention is All You Need” alongside AI, and I must say, linear algebra is both incredibly essential and wonderfully elegant. This experience felt like the first time I delved into neural networks — exciting and eye-opening. From the architecture to the computations to the outcomes, breaking down these astonishing foundational principles is truly rewarding. While this topic isn’t exactly new, taking the time now to organize and reflect on it helps prepare for the continuous evolution of technology. By grounding myself in first principles, I aim to stay firmly rooted amidst the rapidly changing waves of AI innovation.
Below is a thorough comparison between Meta’s Llama series models (including Llama and Llama 2) and the classic Transformer framework. I will detail key design elements, parameters, performance metrics, potential bottlenecks, and future directions. For clarity, I begin with an overview of the classic Transformer, then move step-by-step through the structural modifications, training methods, and real-world performance of Llama and Llama 2.
Revisiting the Classic Transformer Architecture
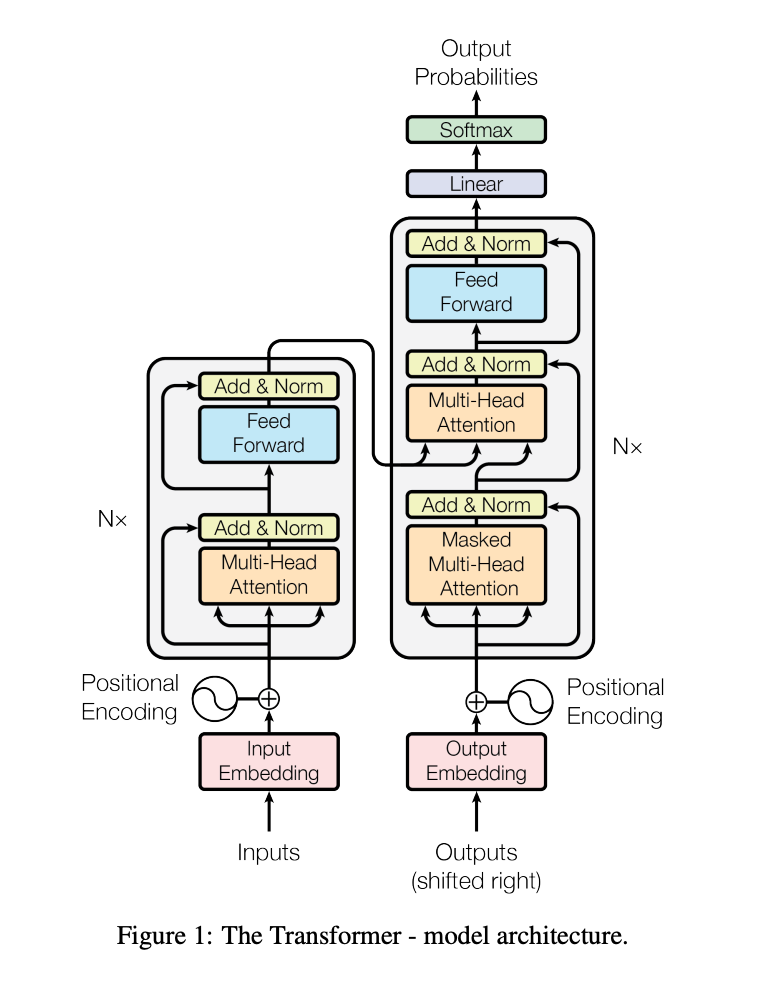
The Transformer architecture was first introduced in the 2017 paper “Attention is All You Need” (Vaswani et al.). Its defining features include:
Encoder-Decoder Dual-Stack Structure
- Encoder: Processes an input sequence (e.g., a sentence) to produce a set of hidden representations.
- Decoder: Uses the encoder’s output, combined with self-attention during decoding, to generate the final output sequence.
- For language modeling tasks, a Decoder-only setup generally suffices for autoregressive text generation.
Multi-Head Attention
- Input vectors are linearly transformed into multiple heads, each performing its own attention mechanism with Q, K, and V.
- The outputs from all heads are concatenated and then linearly projected to form the final output.
Positional Encoding
- The original design uses sinusoidal or cosine positional encoding, converting each position in the sequence into a positional embedding.
Feed-Forward Network (FFN)
- Each attention layer is followed by a feed-forward network for non-linear transformations, typically a two-layer linear mapping with an activation like ReLU.
Layer Normalization (LayerNorm)
- Often applied (either Pre-LayerNorm or Post-LayerNorm) between the attention and FFN components to stabilize training.
Masking Techniques
- In autoregressive language models, the Decoder’s self-attention masks future positions to avoid leaking information about upcoming tokens.
Commonalities Between Llama and the Transformer
Llama, similar to the classic Transformer, is built on the attention mechanism. For autoregressive language modeling, Llama typically uses a Decoder-only structure — mirroring many modern large language models (e.g., the GPT series, or BERT’s Decoder-only extensions).
Overall, Llama retains the following core Transformer elements:
- Self-Attention: Captures dependencies among different positions in a sequence.
- Multi-Head Attention: Learns multiple attention subspaces simultaneously.
- Feed-Forward Network (FFN): Adds a non-linear layer after attention.
- Positional Encoding: While Llama adopts a different scheme (RoPE), the concept of positional embeddings remains.
- Layer Normalization: Used to stabilize deep network training.
Differences Between Llama / Llama 2 and the Classic Transformer
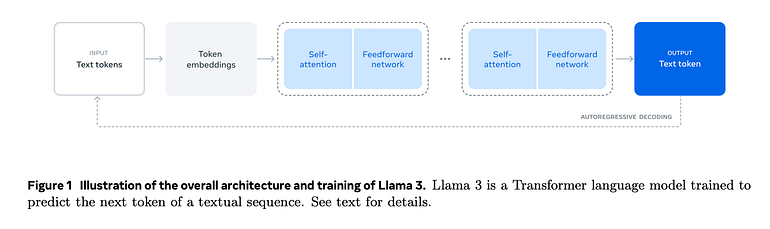
1. Architectural Modifications
Decoder-Only Structure
- Like GPT, Llama focuses on autoregressive language modeling, using the Transformer Decoder while omitting the Encoder.
- This approach is tailored for unidirectional text generation, particularly relevant to chatbots and text-generation tasks.
Positional Encoding: Rotary Positional Embedding (RoPE)
- Instead of traditional sinusoidal/cosine encodings, Llama and Llama 2 employ Rotary Positional Embedding (RoPE).
- RoPE integrates a rotation-based transform into Q and K in the attention mechanism, yielding smoother and more flexible relative positional information.
- Llama 2 features an NTK Scaled enhancement, supporting stable performance over longer contexts (e.g., 4K or even 8K tokens).
Layer Normalization Method: RMSNorm instead of LayerNorm
- Llama extensively uses RMSNorm (Root Mean Square Layer Normalization) in place of the typical LayerNorm.
- RMSNorm computes the root mean square of vector elements, reducing parameters (no bias term) and improving stability/efficiency.
- Llama also adopts a Pre-Norm design (applied before the Attention and FFN layers), mitigating gradient vanishing/exploding in very deep networks.
Activation Function: SwiGLU
- Llama replaces the standard ReLU in the FFN with SwiGLU (Swish-Gated Linear Units).
- Compared to GELU or ReLU, SwiGLU can yield better convergence and performance in large-scale models.
Grouped Query Attention (New in Llama 2)
- Llama 2 introduces Grouped Query Attention (GQA) by grouping the Query heads.
- This reduces memory usage and computational cost with minimal performance impact, by merging Query dimensions into fewer heads while retaining multiple K/V heads.
- Especially for very large models (e.g., 70B parameters), GQA helps significantly lower memory overhead during training/inference.
2. Parameter Counts and Model Sizes
Llama
- Versions: 7B / 13B / 30B / 65B parameters.
- Outperforms GPT-3 (175B) on certain cross-lingual and English benchmarks, demonstrating remarkable parameter efficiency.
Llama 2
- Versions: 7B / 13B / 34B / 70B parameters.
- Uses larger-scale data and refined training strategies (e.g., web content, code), alongside RoPE improvements and GQA, boosting performance at similar model sizes.
- Also offers Chat and Alignment variants tailored for more interactive applications.
3. Performance and Efficiency
Inference and Training Efficiency
- Under similar hardware constraints, Llama’s adoption of RMSNorm, SwiGLU, and RoPE allows it to match bigger models (like GPT-3) in many language tasks with fewer parameters.
- Llama 2’s GQA significantly reduces memory usage and inference time for large models (70B), vital for GPU/TPU-limited environments.
Downstream Tasks (Fine-Tuning / Chat)
- Llama 2 undergoes additional fine-tuning for conversational agents, showing improvements across benchmarks such as MMLU, BBH, ARC, TruthfulQA, etc.
- Compared to Llama 1, it ranks higher in human evaluations — particularly in clarity, fluency, and comprehension.
Alignment and Safety
- Llama 2 emphasizes stricter safety in conversations, improving filters against toxic or biased content.
- Where older Transformer architectures needed special fine-tuning and data sanitization, Llama 2 incorporates these steps more systematically into its training regimen.
Potential Bottlenecks and Challenges
Context Length Limitations
- Despite RoPE’s improvements, long contexts (e.g., beyond 4K or 8K tokens) remain challenging for large language models.
- Extending context length significantly boosts computation and memory requirements, calling for balanced design and hardware solutions.
Memory and Computational Costs
- Massive models demand considerable computational resources, especially for high concurrency and low latency during inference.
- While GQA lowers memory footprints, scaling to hundreds of billions or even trillions of parameters still requires advanced architectural design and distributed training methods.
Data Quality and Alignment
- Model performance hinges on both architecture and the quality/diversity of training data.
- Specialized domains (healthcare, law, coding) need larger, higher-quality datasets, along with careful alignment (safety and ethical) measures.
Legal, Copyright, and Privacy Concerns
- Large language models often scrape data from across the internet, raising potential privacy/copyright issues.
- In conversational apps, developers must carefully handle moderation and misuse prevention.
Llama 3: Further Advancements
Architecture Refinements
- Larger vocabulary size (128K tokens compared to Llama 2’s 32K).
- GQA (Grouped Query Attention) applied across all model sizes for better memory and computation efficiency.
Expanded Context Length:
- Context length increased to up to 128,000 tokens, enabling the model to handle significantly longer sequences compared to Llama 2 (4K tokens).
Improved Multilingual Support:
- Supports 30 languages natively, making it more robust in multilingual applications.
Training Dataset:
- Utilizes a much larger dataset (
15 trillion tokens) compared to Llama 2 (2 trillion tokens), with greater diversity in language and domain coverage.
Potential Multimodal Capabilities:
- Designed with multimodal integration (text, images, and audio) in mind, paving the way for broader AI applications.
Performance Improvements:
- Performance benchmarks show a 20% improvement over Llama 2 models, particularly in reasoning, understanding, and generation tasks.
Conclusion
- The Llama series inherits the Transformer’s core attention mechanism while refining positional encoding (RoPE), normalization (RMSNorm), activation function (SwiGLU), and Grouped Query Attention, aimed at boosting parameter efficiency, inference speed, and memory utilization.
- Llama 2 goes further by refining the training process, dataset scale, and introducing GQA, significantly improving inference efficiency and memory usage, alongside enhanced safety and alignment in conversational settings.
- Llama 3, building on this foundation, expands the vocabulary size, greatly extends context lengths, enhances multilingual support, and prepares for multimodal applications, all while achieving significant performance gains through a larger and more diverse training dataset.
- Despite the impressive advancements, challenges such as hardware resource demands, extended context handling, and data quality persist. Future innovations are likely to focus on more efficient attention mechanisms, expanded multimodal capabilities, and further refinement of alignment and safety.
- Together, these improvements position the Llama series as a powerful and adaptable tool in the rapidly advancing field of AI.